4PL control tower automation
4PL Control Tower Automation That Eliminates Manual Data Entry
We build the full document intelligence pipeline — from email ingestion to CargoWise XML push — that removes every manual step from your control tower operations.
Built For
Who Needs 4PL Control Tower Automation
- 4PL control tower operators managing 50+ shipments/day
- Freight forwarders processing multi-supplier documentation at scale
- Logistics operations teams spending 40%+ of their time on manual data entry into TMS systems
- Companies running CargoWise, SAP TM, or Oracle TMS who want zero-touch document processing
Before FreightMynd
Your ops team is a bottleneck disguised as a process
In most 4PL control towers, a shipment cannot move forward until someone manually reads an email, opens the attached PDF (often 200–300 pages of mixed invoices, packing lists, and AWBs), identifies which pages matter, extracts the relevant data, validates it against business rules, and keys it into CargoWise or your TMS. That takes 15–45 minutes per shipment. Accuracy depends on who's processing and how far into their shift they are. The whole thing breaks down during peak volumes, staff turnover, or when a new supplier shows up with a format nobody has seen before. Shipments stall, exceptions multiply, and your control tower becomes the slowest link in the chain it's supposed to orchestrate.
Ops staff spending 60–70% of their time on manual document processing instead of exception management and client communication
Processing accuracy varies from 85–95% depending on the individual, the document quality, and how far into a shift they are — every error cascading into downstream exceptions
New supplier onboarding takes 1–3 weeks of engineering effort to map each document format, creating a backlog that delays client go-lives
Peak volume spikes (holiday season, port congestion events) cause processing backlogs of 24–72 hours that directly impact SLA compliance
300-page PDF batches from suppliers like Hellmann require operators to manually identify and separate relevant pages — a task that is tedious, error-prone, and unscalable
No audit trail or consistency in how data is extracted — making compliance reporting a manual reconciliation exercise every month
What We Build
4PL Control Tower AI Capabilities
Intelligent email monitoring and auto document ingestion
The system monitors designated inboxes (or shared mailboxes) continuously, identifies shipment-related emails using contextual classification (not just keyword matching), extracts all attachments, and queues them for processing. It distinguishes between actionable documents and noise like read receipts, marketing emails, or duplicate sends — so your pipeline only processes what matters.
AI document filtering — removes irrelevant pages, cuts AI processing costs 50%
Before any extraction begins, a lightweight classifier scans every page of a multi-page PDF and removes blank pages, cover letters, terms and conditions, and other non-data pages. On a typical 300-page supplier batch, this reduces the document set to the 80–120 pages that actually contain shipment data. This cuts downstream AI processing costs by roughly 50% and dramatically improves extraction accuracy by removing noise.
200–300 page batch processing at near-zero failure rate
The pipeline handles large multi-document batches as a single unit of work, splitting them into individual documents (invoice, AWB, packing list), classifying each, and processing them in parallel. The system was stress-tested on Hellmann batches of 300+ pages with near-zero failure rates — meaning no dropped documents, no partial extractions, and no silent errors.
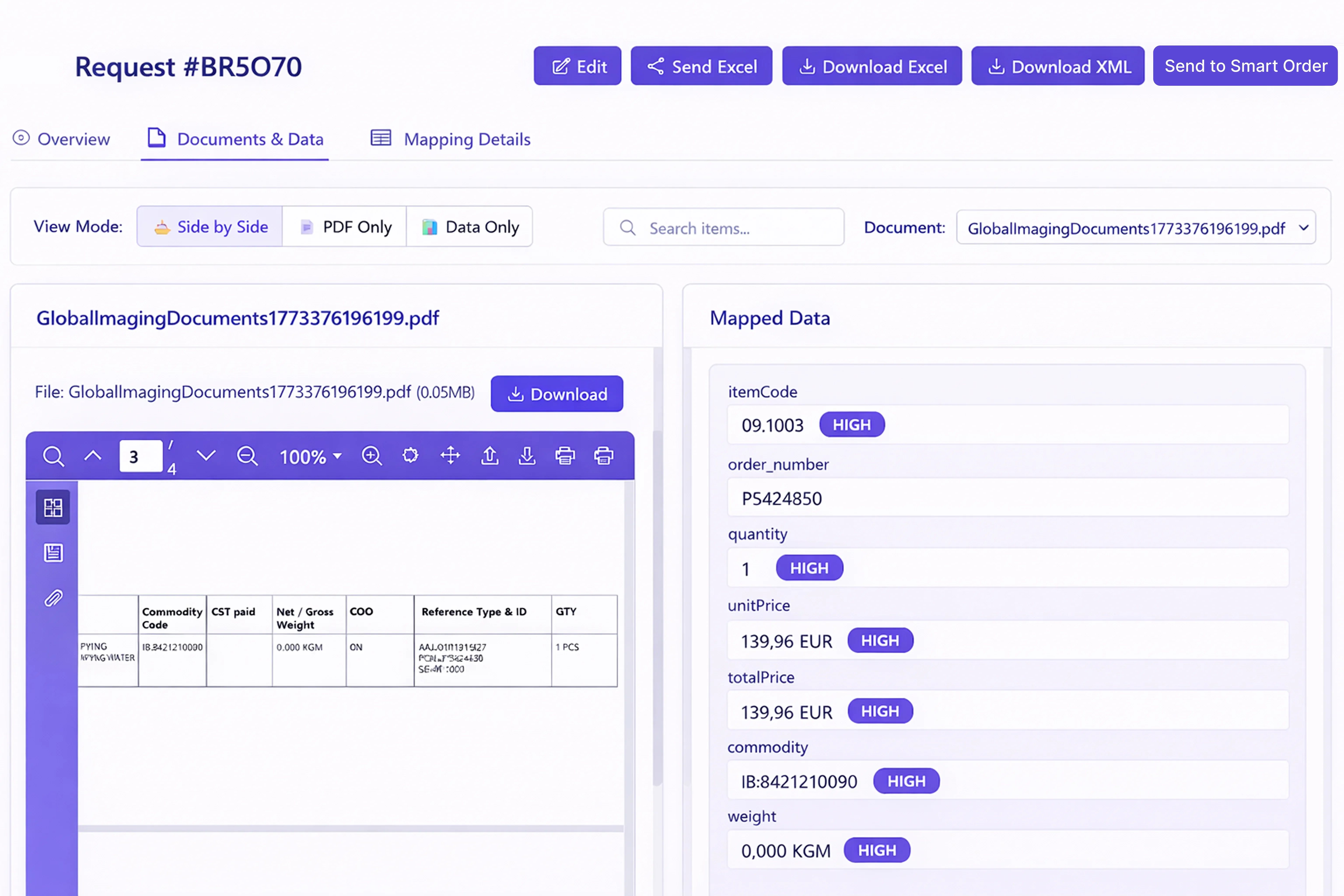
Structured data extraction from invoices, AWBs, and packing lists
Combines OCR, layout analysis, and LLM-based extraction to pull structured fields from all major freight document types. For invoices: line items, charges, surcharges, currency, payment terms, supplier details. For AWBs: origin, destination, weight, dimensions, flight details, shipper/consignee. For packing lists: item descriptions, quantities, HS codes, package counts, marks and numbers.
Validation against business rules before any data moves
Every extracted field is validated against configurable business rules before being pushed to your TMS. This includes: weight/volume cross-checks, rate validation against contracted tariffs, mandatory field completeness checks, supplier-specific rules (e.g., Supplier X always ships DDP, if extraction shows EXW — flag it), and cross-document consistency checks (e.g., does the AWB weight match the packing list totals?).
Direct CargoWise XML integration — no manual TMS entry ever
Validated data is transformed into CargoWise-compliant XML and pushed directly into your instance via the CargoWise eHub or Universal Gateway. The system maps extracted fields to CW1 modules (forwarding, customs, accounting) and handles the complexity of CargoWise's XML schema so your team never needs to touch the TMS for routine document data.
Self-learning supplier onboarding — no engineering per new supplier
When a new supplier sends their first document batch, the system analyzes the layout, field positions, and data patterns to create an extraction template automatically. This template improves over the first 5–10 batches as the model refines its understanding. No developer intervention required — your ops team simply confirms or corrects the first few extractions through a review interface, and the system learns.
Auto-generated Excel compliance reports for ops teams
The system generates daily, weekly, and monthly compliance reports in Excel format, covering: processing volumes, accuracy rates per supplier, exception categories, SLA adherence, and cost tracking. These reports are automatically emailed to designated stakeholders and can be configured per client or per operations manager.
In Practice
4PL Control Tower Use Cases in Production
Hellmann Worldwide Logistics: 300-page batch processing
Hellmann sends consolidated shipment documentation as single PDFs that can be 200–300 pages long, containing mixed invoices, AWBs, packing lists, and certificates for multiple shipments. Previously, an ops team member would spend 2–3 hours per batch manually sorting, extracting, and keying data. With our system, these batches are processed in under 15 minutes end-to-end with near-zero failure rate, freeing the ops team to focus on exception management.
New supplier onboarding without engineering
A 4PL client onboards a new supplier who sends customs invoices in a completely different layout from existing suppliers. Instead of opening a Jira ticket, waiting for engineering to build a new template (typically 1–3 weeks), the AI system processes the first batch, maps the fields with 90%+ accuracy, and auto-improves over the next few batches. The supplier is fully onboarded in days, not weeks.
Peak season volume surge handling
During Q4 peak season, document processing volume increases 3–4x. Instead of hiring temporary staff (who take 2–3 weeks to train and still produce more errors), the system handles the surge with the same accuracy and speed, scaling compute resources automatically. No training. No onboarding. No quality degradation.
Multi-currency invoice validation
A shipment involves charges in USD, EUR, and GBP across multiple invoices. The system extracts all charges, converts to a base currency using configurable exchange rate sources, cross-validates totals against the booking record, and flags discrepancies before any data enters CargoWise — catching the kind of errors that typically surface weeks later during reconciliation.
Implementation
How We Deploy 4PL Control Tower AI
Timeline: 4–8 weeks from kickoff to production
Weeks 1–2: Discovery and audit — map current document workflows, identify all document types and suppliers, catalog business rules and validation logic
Weeks 3–4: Environment setup, TMS integration scaffolding, and initial document pipeline configuration
Weeks 5–8: Core extraction model training on your actual document corpus, business rule implementation, and CargoWise XML mapping
Weeks 9–11: UAT with your ops team processing real documents side-by-side, accuracy benchmarking, exception handling refinement
Weeks 12–14: Production deployment, monitoring setup, team handoff, documentation, and 30-day hypercare support
Results
Measurable Impact
60%
Processing time reduction
50%
AI cost reduction via smart filtering
0
Manual TMS data entry
≈0%
Failure rate on 300-page batches
| Metric | Result | Context | Business Outcome |
|---|---|---|---|
| Processing time reduction | 60% | Measured against manual processing of equivalent document volumes at Hellmann Worldwide Logistics | Equivalent to reclaiming 2+ FTEs of operational capacity |
| AI cost reduction via smart filtering | 50% | By removing irrelevant pages before LLM extraction, reducing token consumption by half | Lower ongoing operational costs as document volume scales |
| Manual TMS data entry | 0 | All validated data pushed directly into CargoWise via XML — zero human keying required | Eliminates data entry errors and costly exception handling |
| Failure rate on 300-page batches | ≈0% | Stress-tested on production Hellmann document batches with no dropped or partially processed documents | No lost documents, no re-processing, no supplier follow-ups |
Measured against manual processing of equivalent document volumes at Hellmann Worldwide Logistics
Equivalent to reclaiming 2+ FTEs of operational capacity
By removing irrelevant pages before LLM extraction, reducing token consumption by half
Lower ongoing operational costs as document volume scales
All validated data pushed directly into CargoWise via XML — zero human keying required
Eliminates data entry errors and costly exception handling
Stress-tested on production Hellmann document batches with no dropped or partially processed documents
No lost documents, no re-processing, no supplier follow-ups
Works with your existing TMS
Direct integration with CargoWise, SAP TM, Oracle TMS, Microsoft Dynamics, and Descartes.
4PL Control Tower — Frequently Asked Questions
What is 4PL control tower automation?
Does this integrate with CargoWise?
How long does implementation take?
Can it handle multiple document formats from different suppliers?
What happens when the AI is uncertain about a document?
How does this handle data security and compliance?
What if we switch TMS providers in the future?
How does pricing work?
Related Freight AI Solutions
Document Intelligence
AI-powered extraction and processing of freight documents — invoices, AWBs, packing lists, customs forms — with 99%+ accuracy.
Document Automation
Automate freight document processing — invoices, AWBs, bills of lading, customs forms. AI extraction with 99%+ accuracy and direct TMS integration.
TMS Automation
Automate your TMS with AI — zero manual data entry, intelligent document routing, and native API integration with CargoWise, SAP TM, Oracle TMS.
Email Intelligence
AI-powered email triage that classifies, routes, and auto-responds to freight operations emails — RFQs, booking confirmations, shipment updates, and exceptions — without human intervention.
SOP Compliance
AI that continuously audits every shipment against your SOPs and business rules — catching violations, missing data, and process deviations before they become exceptions or customer complaints.
Ready to Automate Your 4PL Control Tower?
Book a free audit. We'll show you exactly what we'd build for your operations.